Dynamics 365 F&O Integration Case Study: Part I
Introduction⌗
Recently, I worked on a client project that required us to track changes made on the client’s Microsoft Dynamics 365 Finance & Operations module and integrate those data changes on the destination application. As a team we learned quite a bit on how to design and implement a solution to this scenario and we wanted to share insights and tips for anyone needing to develop a pipeline similar to ours.
The Stack⌗
For this project, we had a source system made up of a relational source database in MSSQL, sitting behind Microsoft Dynamics 365 and a destination system composed of a web application with a supporting database on MongoDB. The source database has a feature called “CDC”, or Change Data Capture that can be configured to track changes at the table level. In our use case, these changes needed to be captured at the MongoDB side as they happen in the SQL database. Our pipeline was designed to use an event driven architecture, using RabbitMQ as our message broker. The destination components included a consumer service subscribed to our broker’s topic, and a MongoDB cluster as the destination database where the data changes are capture. The components of the pipeline include Azure Functions, Logic Apps, and blob storage as the middleware. I’ve included a visual of the design of the system from a high level for a complete look at all the different components.
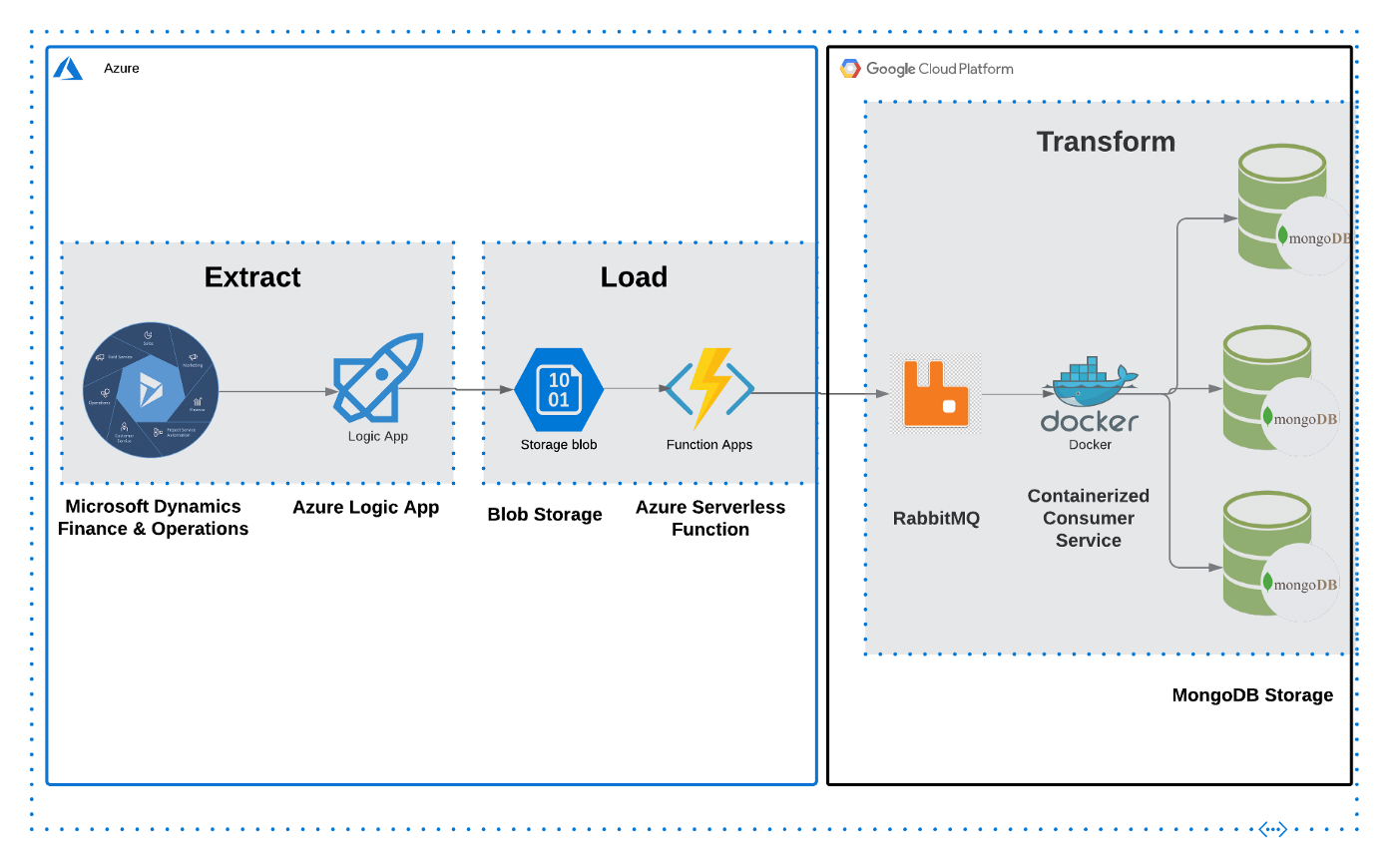
The Articles⌗
To mirror the development process, this study will be broken into different articles, each one focused on a different layer or stack of our architecture. We will start with the source system and database (Microsoft Dynamics & MSSQL), followed by the middleware (Azure Logic Apps & Azure functions) and finally, the destination system (message broker, consumer service, and MongoDB database).
The Articles in this series:⌗
Part I: The Source System (see below)
Part II: The Middleware
Part III: The Destination System
References⌗
Part of the design and development process always involves a bit of research, and I wanted to both credit the sources of information that helped us during our research and also provide other resources for anyone who will be taking on projects similar to ours.
Here are some of the sources we used during our research:
https://docs.microsoft.com/en-us/dynamics365/fin-ops-core/fin-ops/
https://docs.microsoft.com/en-us/dynamics365/fin-ops-core/dev-itpro/data-entities/data-entities
https://blog.crgroup.com/dynamics-365-latest-feature-the-data-export-service/
https://www.encorebusiness.com/blog/logic-apps-in-dynamics-365-fo-file-based-data-integrations/
https://medium.com/hitachisolutions-braintrust/logic-app-integration-with-d365-f-o-524ac4909f0
https://azureintegrations.com/2019/10/15/d365fo-interacting-with-data-management-frame-work-using-rest-api-for-delta-changes-on-entity/
https://github.com/Microsoft/Dynamics-AX-Integration/wiki/File-based-integration-using-Logic-Apps
Part I⌗
The Source⌗
For this project, our data source was the Microsoft Dynamics 365 Finance & Operations web application sitting on top of a SQL database. An important characteristic of this source is that it is a relational database, as opposed to the destination database, which is a document based database.
Relational Databases⌗
Relational databases tend to be the industry standard for most groups and organizations because to be frank, these databases have been in place longer than the other types and have the most support amongst vendors and enterprise clients. Most developers and database admins learn their trade using relational databases, and they are the de facto standard in the industry. The key characteristics of these databases are as follows:
- Database is managed by RDBMS or “Relational Database Management System”
- Data is structured in rows and columns based on pre-defined relationships
- Data can be manipulated using SQL (Structured Query Language)
- Rows represent a collection or grouping of related values
- Columns represent a certain kind of data
- Rows almost always have a “primary key”, used as an unique identifier
- Popular relational databases include MSSQL, MySQL, Oracle, and PostgreSQL
Microsoft SQL Server⌗
Now that we’ve covered the general idea of relational databases, we will go over some of the product specific traits of SQL Server. The first thing to note is that Microsoft SQL Server and the shorter “MSSQL” acronym are interchangeable in industry, so just remember that they are one and the same.
Microsoft’s SQL Server is one of the most popular enterprise databases and tends to come up quite a bit on client projects (including the one that inspired this post). In the past, Microsoft wasn’t exactly “open source” friendly and using their product would have required purchasing a license key and going through the process of setting up the system as a customer. Thankfully, they have taken different attitudes in recent years and expanded their offerings to allow for easier deployments and no upfront costs for use. Due to this, if you’re following this project and don’t have access to a client’s MSSQL, you can launch an non-production MSSQL database using Docker.
Microsoft Dynamics 365 Finance & Operations⌗
Originally known as Microsoft Dynamics AX, this system is focused on medium and large organizations and enterprise resource planning. Within the Dynamics ecosystem, the data that we are interested in is expressed as “Data Entities” which are essentially custom views composed of fields from the base tables. The purpose of “Data Entities” is to abstract the data from the base tables to business specific terms for non-technical users (an example could be an “Employees” entity, which could bring in fields from 4 different base tables that store information relevant to employees). For our project, the data entities that needed to be transferred from source to destination came from what is referred to as “Export Jobs”. These export jobs are created using the web interface, which provides both a layer of convenience and safety since the data does not have to be directly pulled from the database. This interface meant that we did not need to create custom queries or stored procedures to get the data out. I’ve included some images below to demonstrate the features I’m talking about:
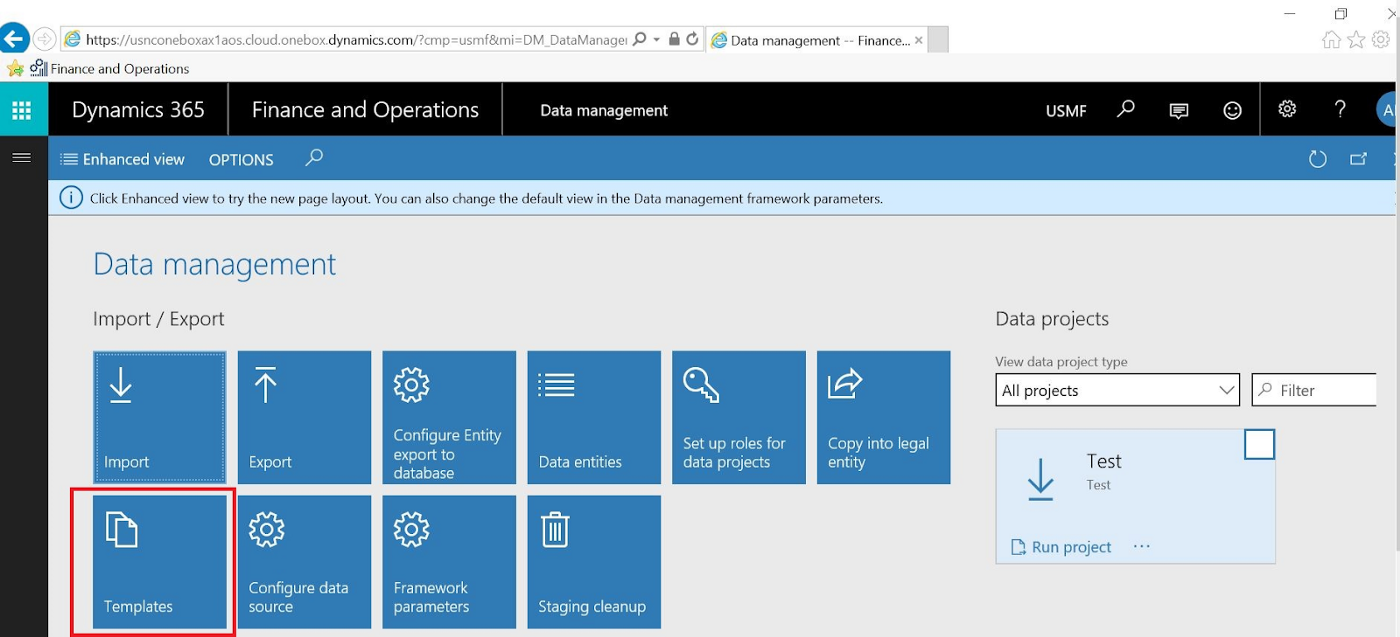
Ignore the red box, we’re interested in the Export button
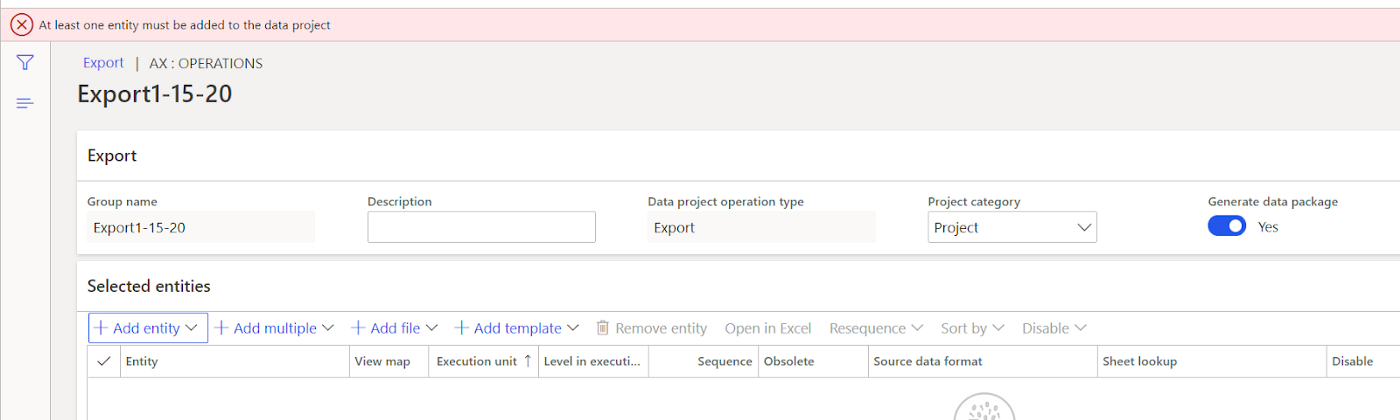 The Add Entity button allows us to configure each job with the data we are interested in
The Add Entity button allows us to configure each job with the data we are interested in
Setting Up the Source Components⌗
From a technical perspective, this source system requires the least amount of work. To set up the rest of the pipeline, we simply created “Export Jobs” for all the data entities we were interested in transferring to our destination system by adding the entities to the jobs on the configuration screen. In our particular case, we configured the jobs to export the data as CSV file extracts, but it is possible to export the data as Excel extracts or other file/data types. The key requirement for our project was that we weren’t interested in exporting all the data every time, we were interested in only the data that had changed (“Change Data Capture”). To make sure we were only transferring this specific data, we made sure to enable change data tracking on every entity we were interested in. Once this was enabled, only data that changed would be exported after the first initial data dump. You can do this using the web interface, in the Entities module.

To be clear, you should enable CDC for each entity before creating the Export Job
Source System Conclusion⌗
Reading this section, you might be struck by the simplicity in this stage of our pipeline. Due to the abstraction that is provided by the Dynamics web application, we were saved from having to directly interact with the underlying database. To summarize what we did here, we simply enabled change tracking on the entities we are interested in transferring and then created the corresponding export jobs. In the next post, we’ll explore how we tie these export jobs into the rest of the pipeline and our event driven design using a couple different Azure services.